Will Agentic AI Replace Classic ML? Wrong Question.
Agentic AI isn't going to out-predict your gradient booster, and that was never the point. The real shift is that the agent isn't the model. It's the modeller.
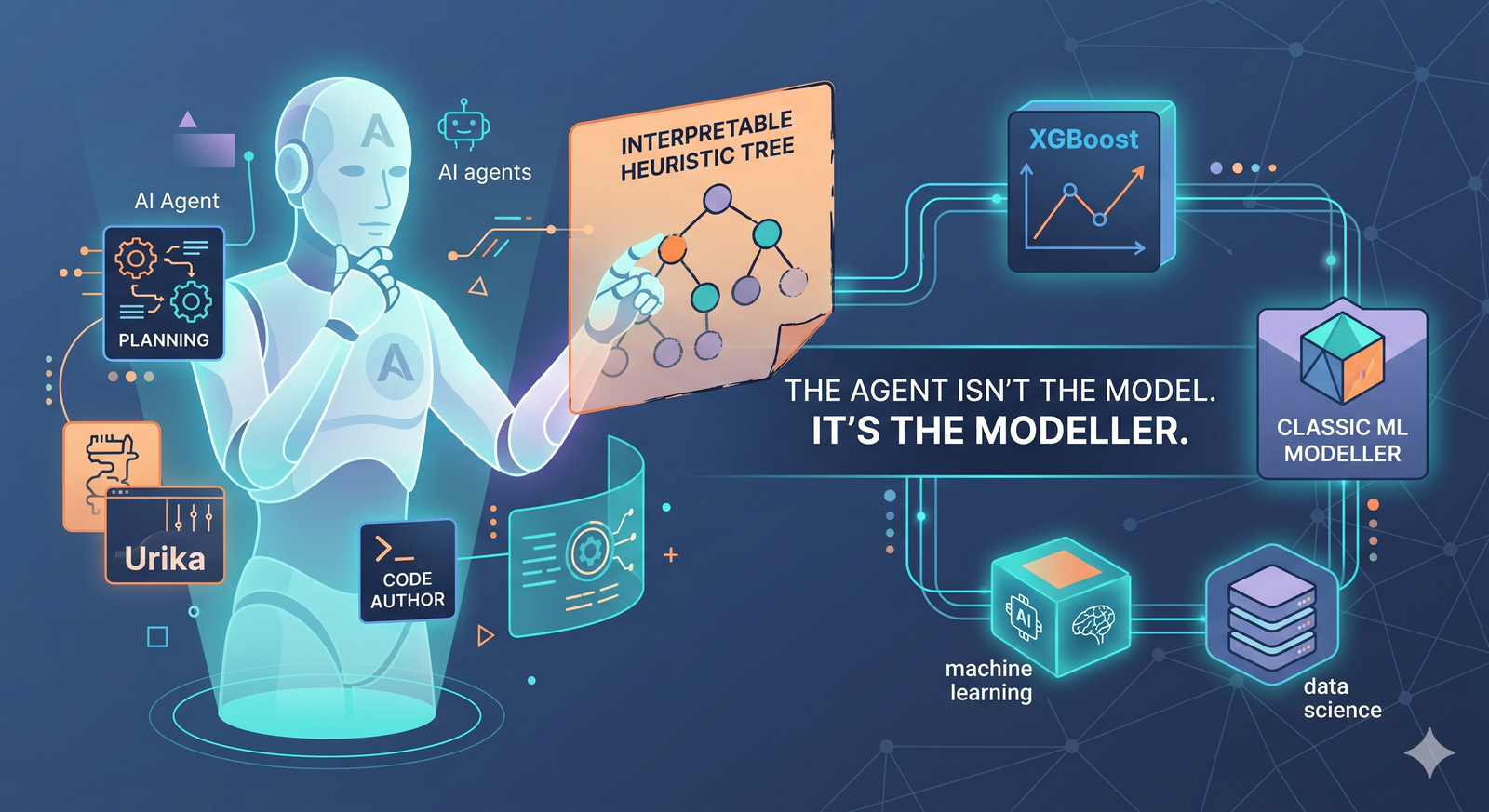
I’ve noticed something about how I work lately. When I need to model or predict something, some behaviour, or a pattern buried in a messy dataset, I no longer reach first for a random forest, an SVM, or a neural network. I hand the problem to an agent.
So is agentic AI replacing classic machine learning? It’s the wrong question.
The honest answer first
On raw predictive accuracy, no, and it’s worth saying so plainly. Classic, data-driven ML still wins, especially on large, clean datasets. The research is candid about this. When researchers had an LLM build interpretable decision trees from world knowledge alone, those trees beat their data-driven counterparts on barely a quarter of datasets. This is now a properly surveyed field, not hype, and the honest work in it doesn’t pretend the accuracy gap isn’t there.
If someone tells you an agent will out-predict your gradient booster on a big tabular dataset, they’re overselling.
Why the gap is real
The reason is almost information-theoretic. An agent’s advantage comes from prior knowledge. It knows that income predicts loan default before it sees a single row. That’s worth an enormous amount when you have fifty data points. But on a large, clean dataset the signal is already in the data, and a well-tuned booster extracts it close to optimally. The ceiling is set by the data, not by the method.
Better agentic structure (smarter search, more careful refinement) keeps closing the gaps where structure was the bottleneck. But no amount of agentic cleverness conjures signal the data doesn’t contain. “It’s just a matter of time” is half right: time will close some gaps, but not that one.
The agent isn’t the model, it’s the modeller
The agent was never meant to be a better curve-fitter than XGBoost. Its job is to choose and build the method, and increasingly to do it programmatically, refining the artifact as it goes. It can train a classic model when that’s the right tool, or wrap an intrinsically interpretable one when transparency matters. And when nothing off the shelf fits, it writes something bespoke.
This is exactly why I built Urika, my multi-agent analysis platform. You give it a dataset and a question, and it writes a fresh method for that problem, not a template pulled off a shelf. Sometimes that means training and tuning a classic model and handing you a leaderboard of what worked. Sometimes the planning agent decides a capability is missing and builds a new tool on the fly.
And sometimes the best “model” isn’t a trained classifier at all. In much of my behavioural-modelling work, what actually serves best is a heuristic decision tree the agent authors directly, and can re-shape programmatically for each persona or individual I’m trying to model. It’s transparent, it works with very little data, and I can bend it to the problem instead of bending the problem to fit an algorithm.
That’s the trade, and it’s worth naming clearly: you give up a little accuracy, and in return you get a model you can read and audit. For the high-stakes work where data is thin and the call has to be explained (most of academic and applied behavioural science), that’s frequently the right trade.
So, will it replace classic ML?
No. It’ll do something more useful: pick classic ML up when it’s the right tool and put it down when it isn’t, then build whatever the problem actually needs. The frontier was never about out-predicting XGBoost. It’s about everything XGBoost was never trying to do.
Michael Richardson Professor, School of Psychological Sciences Faculty of Medicine, Health and Human Sciences Macquarie University
AI Disclosure: This article was written with the assistance of AI tools, including Claude. The ideas, opinions, and experiences described are entirely my own. The AI helped with research, drafting, editing, and structuring the text. I use AI tools extensively and openly in my research, teaching, and writing, and I encourage others to do the same.